



Оцениваю свои навыки владения Google Таблицами на троечку, но даже этого достаточно, чтобы выдернуть объём информации в 1000-1500 строк и в десяток столбцов.
Основная проблема
В сети по вопросу парсинга с помощью Google таблиц можно встретить проблему ограничения количества запросов, которые можно отправить формулами во внешний сайт. Кто умеет писать код решает кодом. Я не умею, зато у меня есть +100500 аккаунтов Google, которые разделят поток обходя ограничение.
Парсим ссылки
Первым делом идёт список ссылок на все товары чужого интернет магазина, для этого использовал формулу:
Это позволило дернуть все ссылки со страницы всех товаров (такая была на сайте донере), но присутствовала пагинация (еще 19 страниц). Поэтому так пришлось сделать 19 раз.
Фильтруем ссылки
Так как собирали все ссылки со страницы, а нам нужны только те, что ведут на товар, то соединим все ссылки в 1 столбец можно накинуть фильтр и далее
Это позволит увидеть только те ссылки, что вели на страницу товара (но это в моём случае, в вашем может быть иначе)
Парсим изображения
Когда есть список со всеми товарами, нужны их фото. У товара может быть несколько фото, но мне пока нужно только 1. Проблема в том, что при использовании простой формулы как на скриншоте ниже возвращалось сразу 3 одинаковые ссылки в столбце.

Не зная этого Я решал проблему массовым добавлением 2 пустых строк к каждой ссылке на продукт. Это увеличило число строк в общем на более чем 3000 строк. И только потом я узнал, что есть возможность ограничить поток возвращаемых данных от запроса 2 формулами:
и
Парсим описание
Имея на вооружении такие формулы уже не проблема достать описание товара, надо только корректно вставить в формулу class
Следующую ниже формулу Я использовал, чтобы достать маркированные списки, каждый элемент из которого попадал в отдельный столбец. (ограничил 15 столбцами)
А если в описании не было маркированных списков, то просто:
Напомню, что всё это делалось в режиме многопоточности с разных аккаунтов и тут надо было проявить терпения и сноровку, чтобы разбить массив на доли, которые может пропарсить 1 аккаунт (это примерно 100 запросов за 1 раз)
Парсим цены
Вариантов цен два - это просто цена и старая цена (зачеркнутая) и просто цена. Сайт донор на WordPress с модулем Woo-Commerce, который не содержит цены с походими тегами, что предыдущие значения. Тут пришлось использовать
Форматируем цены
Возвращенные значения были
- на конце с “руб.”
- между тысячи иногда пробел, а иногда запятая
Если были старая цена, то она шла первой, а обычная второй, поэтому при парсинге там, где в столбце Price должна быть обычная возвращалась зачеркнутая (OldPrice)
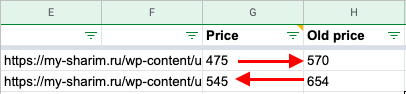
Далее сначала убираем пробелы и запятые через “Найти и заменить” в нужных столбцах, а потому убираем “руб.”, чтобы подровнять всё под единый формат чисел.
Вывод
По работе мне постоянно приходиться выбирать 1 из 2 способов решения проблемы. Это либо “капать яму лопатой” долго, но весьма предсказуемо по времени. Это брать и вытаскивать кажду ссылочку ручками и делать Ctrl + С и потом Ctrl + V. Или потратить n-количества времени на “создание экскаватора и выкопать” за 5 минут.
Вот сколько у меня заняло времени (скриншот ниже) сделать экскаватор, при том что я просто знал что это можно, но никто готовые формулы мне не давал (как Я вам сейчас) и тыркаться в основном приходилось с кодом чужого сайта, чтобы понять какие class и span выбрать для того, чтобы вернулось формулой то что нужно.
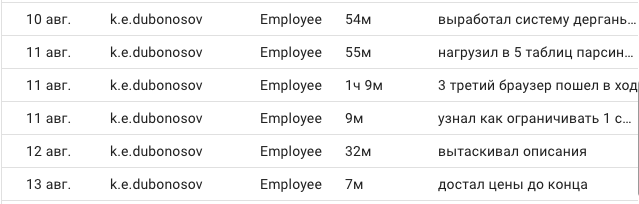
А еще выбор между лопатой и экскаватором обычно стоит очень остро и решать нужно быстро. Особенно трудно оценить свой уровень знаний, настойчивость в поиске нужной информации для решения задачи и сколько же в итоге времени займет разработка экскаватора, который ты никогда раньше не делал.
В итоге у меня появились знания и некоторый навык для того, чтобы провести эту операцию с несколькими сайтами. К сожалению, с лопатой это так не работает.
Успехов!








